-
javscript中的OOP特性
1 引言
js也是具有OOP(object oriented programming)特性的,OOP在构建一些大型应用程序还是有一套成熟理论的。作为C++的使用者在学习js中的OOP特性的过程中,能够较快地理解其中的各种术语和概念,也能比较两种语言的异同,深化知识理解。通过js的OOP特性的学习也让我开始从语言层面考虑程序设计问题。
本篇文章主要介绍了js中的一些OOP特性,并且比较了js与C++的语言特性。如果你能熟练掌握C++的OOP特性,本文能帮助你快速地对js中的OOP特性建立整体的认识。2 写给C++使用者的js中的OOP特性介绍
2.1 创建对象(object)
js中创建object的代码,示例如下:
let duck = { name: "Aflac", numLegs: 2, sayName: function() { return "The name of this duck is " + this.name + "."; } };js直接通过
{}就可以创建出对象示例来,不需要对该对象(object)的类(class)进行声明。这点和C++不是很相同,C++需要先声明一个class再创建object。
这个object有两个成员变量和一个成员函数,需要注意的是这两个成员变量都是公有(public)的,他们是可以直接用.符号访问的。
js中也有this关键字,与C++相同,this关键字用于表示当前实例。2.2 类(class)的声明
js中声明一个类的操作实际上就是声明一个构造函数。
let Bird = function(name, color) { this.name = name; this.color = color; this.numLegs = 2; } let crow = new Bird("Alexis", "black"); crow instanceof Bird; // => true上面的代码声明了Bird类,在js中通常类的名字都是由首字母大写的单词表示的。类的构造函数也能接受参数用于对实例的初始化,这点与C++非常相似,使用
new关键字就能够创建该类的实例。
使用instanceof关键字用于检查对象是否属于某个类,也可通过验证constructor属性来判断一个对象是否属于一个类crow.constructor == Bird。2.3 类的共有成员
js中通过
prototype这一属性(把它叫做关键字好像还不太合适)能够实现C++中静态成员变量和静态成员函数的特性。Bird.prototype.numLegs = 2;
上面的代码就给Bird类增加了一个静态成员变量。这个
prototype可以是一个对象,这样类的共有成员就能方便地承载更多的属性了,示例代码如下。Bird.prototype = { constructor: Bird, numLegs: 2, eat: function() { console.log("nom nom nom"); }, describe: function() { console.log("My name is " + this.name); } };需要注意的是需要设置好
constructor属性,这样是为了保证代码逻辑的一致性。
对象会获得类的prototype属性,可以通过isPrototypeof方法来验证。Bird.prototype.isPrototypeOf(duck);
2.4 类的私有成员
js与C++一样,也可以有私有成员变量,代码如下所示。
hatchedEgg就相当与是Bird的私有成员变量,并且提供了修改这个成员变量的方法getHatchedEggCount。function Bird() { let hatchedEgg = 10; // private property this.getHatchedEggCount = function() { // publicly available method that a bird object can use return hatchedEgg; }; } let ducky = new Bird(); ducky.getHatchedEggCount(); // returns 10这种形式在js中被称作闭包(closure),函数能够访问到与他处在同一个作用域(context)中的变量。
2.5 类的继承和派生
js中的派生主要通过
prototype体现,下面的代码表示Bird派生自Object。同样,需要注意将constructor属性设置好。Bird.prototype = Object.create(Animal.prototype); Bird.prototype.constructor = Bird;
2.6 类的覆盖
js中可以重写基类中的方法,代码如下所示,这点与C++中的
override相同。function Animal() { } Animal.prototype.eat = function() { return "nom nom nom"; }; function Bird() { } // Inherit all methods from Animal Bird.prototype = Object.create(Animal.prototype); // Bird.eat() overrides Animal.eat() Bird.prototype.eat = function() { return "peck peck peck"; }; Bird.prototype.fly = function() { console.log("I'm flying!"); };通样也在派生之后也可以通过修改派生类的
prototype以达到特化派生类的作用,上面的fly方法就是在Bird完成派生之后新增的方法。现在Bird有两个方法,它们分别是eat和fly。3 参考资料
-
js正则表达式备忘
引言
近在FreeCodeCamp(FCC)学习前端的课程,其中有一节就是讲的
regexp,也就是正则表达式。我之前零星地了解过一些正则表达式的相关知识,但不足以对正则表达式得出一个完整的认识。FCC的教程循序渐进,由简到繁,在教学中结合练习,非常适合初学者的学习过程。如何你的英文能够达到阅读技术类文献的水平,又正好想学习一下正则表达式,我推荐你试一下FCC的正则表达式教程,花3~4个小时就能够对正则表达式有个完整的理解。教程使用的编程语言是javascript,需要注意的是不同语言之间的正则表达式在某些细节上还是略有区别的。
本篇文章主要是对学习过程中的知识点进行总结,方便以后进行查阅。
要点总结(js版)
FCC的教程使用javascript作为开发语言,本节所有的代码都是js代码。
js中内置了正则表达式模块,下面是正则表达式在js中的使用示例
let myString = "Hello World"; let myRegex = /Hello/; let result = myRegex.test(myString);
使用
|进行or匹配let regex2 = /cat|bird/;
使用
i标识符在匹配时忽略大小写let regex3 = /case/i;
使用正则表达式进行字符串过滤,使用
match方法let extractStr = "Extract the word 'coding' from this string."; let codingRegex = /coding/; // Change this line let result = extractStr.match(codingRegex); // Change this line
使用
g进行返回满足规则的多次结果,g为global的缩写let twinkleStar = "Twinkle, twinkle, little star"; let starRegex = /twinkle/gi; // Change this line let result = twinkleStar; // Change this line
使用
.匹配所有的字符,使用[]匹配指定的字符let quoteSample = "Beware of bugs in the above code; I have only proved it correct, not tried it."; let vowelRegex = /[aeiou]/gi; // Change this line let result = quoteSample.match(vowelRegex); // Change this line
在
[]中可以使用-代表一个范围let quoteSample2 = "The quick brown fox jumps over the lazy dog."; let alphabetRegex = /[a-z]/gi; // Change this line let result = quoteSample2.match(alphabetRegex); // Change this line
这个范围还可以是多个,并且允许包含数字
let quoteSample3 = "Blueberry 3.141592653s are delicious."; let myRegex = /[h-s2-6]/gi; // Change this line let result = quoteSample3.match(myRegex); // Change this line
使用
^符号能够匹配不包含某些字符let quoteSample4 = "3 blind mice."; let myRegex2 = /[^0-9aeiou]/gi; // Change this line let result = quoteSample4.match(myRegex2); // Change this line
使用
+对出现连续出现的字符进行匹配let difficultSpelling = "Mississippi"; let myRegex3 = /s+/g; // Change this line let result = difficultSpelling.match(myRegex3);
使用
*星号匹配可能没有出现的次数(出现次数为 0~n 次)let chewieQuote = "Aaaaaaaaaaaaaaaarrrgh!"; let chewieRegex = /Aa*/; // Change this line let result = chewieQuote.match(chewieRegex);
使用
?进行较短匹配 (lazy match, 与greedy match 对应)let text = "<h1>Winter is coming</h1>"; let myRegex = /<.*?>/; // Change this line let result = text.match(myRegex);
使用
^对出现在字符串开始位置进行匹配
注意上边也用到这个符号表示取反,是在[]中表示取反let rickyAndCal = "Cal and Ricky both like racing."; let calRegex = /^Cal/; // Change this line let result = calRegex.test(rickyAndCal);
使用
$对出现在字符串结束位置进行匹配let caboose = "The last car on a train is the caboose"; let lastRegex = /caboose$/; // Change this line let result = lastRegex.test(caboose);
使用
\w代替[A-Za-z0-9_],包含所有的数字、字母和下划线let quoteSample = "The five boxing wizards jump quickly."; let alphabetRegexV2 = /\w/g; // Change this line let result = quoteSample.match(alphabetRegexV2).length;
使用
\W代替[^A-Za-z0-9_],相当于上边的逆向匹配let quoteSample = "The five boxing wizards jump quickly."; let nonAlphabetRegex = /\W/g; // Change this line let result = quoteSample.match(nonAlphabetRegex).length;
使用
\d代替[0-9],所有数字匹配let numString = "Your sandwich will be $5.00"; let numRegex = /\d/g; // Change this line let result = numString.match(numRegex).length;
使用
\D代替[^0-9],所有非数字匹配let numString = "Your sandwich will be $5.00"; let noNumRegex = /\D/g; // Change this line let result = numString.match(noNumRegex).length;
使用
\s代替[ \r\t\f\n\v],与空格和换行相关let sample = "Whitespace is important in separating words"; let countWhiteSpace = /\s/g; // Change this line let result = sample.match(countWhiteSpace);
使用
\S=,代替 =[^ \r\t\f\n\v],不包含空格和换行let sample = "Whitespace is important in separating words"; let countNonWhiteSpace = /\S/g; // Change this line let result = sample.match(countNonWhiteSpace);
使用
{min, max}对字符出现的次数进行限定
回想起使用+限制次数为{0,},使用-限制次数为{1,}let ohStr = "Ohhh no"; let ohRegex = /Oh{3,6} no/; // Change this line let result = ohRegex.test(ohStr);
仅限制出现次数的下限
{min,}let haStr = "Hazzzzah"; let haRegex = /Haz{4,}ah/; // Change this line let result = haRegex.test(haStr);
指定出现的次数
{count}let timStr = "Timmmmber"; let timRegex = /Tim{4}ber/; // Change this line let result = timRegex.test(timStr);
使用
?匹配可能出现的字母
问号用于声明lazy match,如何判断是lazy match还是匹配可能出现的东西呢let favWord = "favorite"; let favRegex = /favou?rite/; // Change this line let result = favRegex.test(favWord);
lookahead 的概念,
(?=...)与(?!...)下面的正则表达式用于检查密码,由3~6个字母和至少1个数字组成
let password = "abc123"; let checkPass = /(?=\w{3,6})(?=\D*\d)/; let result = checkPass.test(password); // Returns true
下面的正则表达式用于检查密码,有5个以上的字符和至少2个数字组成
let sampleWord = "astronaut"; let pwRegex = /(?=\w{5,})(?=\D*\d{2,})/; // Change this line let result = pwRegex.test(sampleWord);
截取字符串中的重复部分,使用括号 () 对内容进行补充,是用 \1 表示第一个捕捉到的字符
let repeatNum = "42 42 42"; let reRegex = /^(\d*)\s\1\s\1$/; // Change this line let result = reRegex.test(repeatNum);
通过截取字符串,可以对截取的字符串进行修改或替换操作,需要使用
replace方法"Code Camp".replace(/(\w+)\s(\w+)/, '$2 $1'); // Returns "Camp Code"
下面的正则表达式就是用于将
good替换为okey-dokeylet huhText = "This sandwich is good."; let fixRegex = /good/; // Change this line let replaceText = "okey-dokey"; // Change this line let result = huhText.replace(fixRegex, replaceText);
使用正则表达式实现类似
.trim()的功能let hello = " Hello, World! "; let wsRegex = /^\s+|\s+$/g; // Change this line let result = hello.replace(wsRegex, ''); // Change this line
elisp和python中的正则表达式
在emacs中内置了
string-match函数进行正则表达式匹配,其函数原型为(string-match REGEXP STRING &optional START),下面就是在emacs中使用regexp的示例。(setq str-regexp "\.[h|cpp]$") (setq str-sample-1 "sample1.h") (string-match str-regexp str-sample-1)
python中内置了
re模块用于正则表达式匹配,下面就是在python中的regexp示例。import re pattern = r"Cookie" sequence = "Cookie" if re.match(pattern, sequence): print("Match!") else: print("Not a match!")
-
每周算法:字符串转整数
Description
Implement
atoiwhich converts a string to an integer.The function first discards as many whitespace characters as necessary until the first non-whitespace character is found. Then, starting from this character, takes an optional initial plus or minus sign followed by as many numerical digits as possible, and interprets them as a numerical value.
The string can contain additional characters after those that form the integral number, which are ignored and have no effect on the behavior of this function.
If the first sequence of non-whitespace characters in str is not a valid integral number, or if no such sequence exists because either str is empty or it contains only whitespace characters, no conversion is performed.
If no valid conversion could be performed, a zero value is returned.
Note:
Only the space character ' ' is considered as whitespace character.
Assume we are dealing with an environment which could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. If the numerical value is out of the range of representable values,INT_MAX(231 − 1) orINT_MIN(−231) is returned.Example 1:
Input: "42"
Output: 42Example 2:
Input: " -42"
Output: -42
Explanation: The first non-whitespace character is '-', which is the minus sign.
Then take as many numerical digits as possible, which gets 42.Example 3:
Input: "4193 with words"
Output: 4193
Explanation: Conversion stops at digit '3' as the next character is not a numerical digit.Example 4:
Input: "words and 987"
Output: 0
Explanation: The first non-whitespace character is 'w', which is not a numerical
digit or a +/- sign. Therefore no valid conversion could be performed.Example 5:
Input: "-91283472332"
Output: -2147483648
Explanation: The number "-91283472332" is out of the range of a 32-bit signed integer.
TheforeINT_MIN(−231) is returned.Solution
Approach 1
这道题并不难,思路也比较容易想出来,下面就是我想到的解法。
可能需要注意的问题是:- 字符到数字的转换,这个涉及到ascii码表的记忆,如果记不住了可以直接使用'0' 'a' 'A'
- 对于溢出的判断,我一开始只想到了使用
int temp=num*10; if (temp/10!=num)进行判断,实际上却忽略了2147483648(0x80000000)的边界情况,这个是需要特别注意的。
int parseChar(char ch) { int num = ch - '0'; if (num > 9 || num < 0) { return -1; } return num; } int myAtoi (string str) { bool isNegative = false; bool isOverflow = false; int num = 0; // 从前向后进行转换 size_t pos = 0; // 去除多余的空格 while (str[pos] == ' ') { ++pos; } // 首先判断是否有符号位 if (str.length() > 0) { if (str[pos] == '-') { isNegative = true; ++pos; } else if (str[pos] == '+') { ++pos; } } // 是否以数字进行开头 // 从左向右读取数字,每次读取需要判断是否溢出 for ( ; pos < str.length(); ++pos) { int digit = parseChar(str[pos]); if (digit < 0) { // 负数说明该位不是数字了 break; } // 如何判断是否溢出 int temp = num*10; if (temp/10 != num) { isOverflow = true; break; } num = temp + digit; } // 如果num变成负数,也是溢出了,相当于对最后一位检查溢出 if (isOverflow || num < 0) { return isNegative ? INT_MIN : INT_MAX; } return isNegative ? -num : num; }
Approach 2
下面这段代码目前是leetcode上运行速度最快的solution sample,仅仅耗时了4ms。作者使用了很多让程序跑得更快的方法,其中的技巧值得我学习。
static int fast = []() { ios_base::sync_with_stdio(0); cin.tie(0); cout.tie(0); return 0; }(); class Solution { public: int myAtoi(string str) { long long sum = 0; int base=10; int n = str.size(); bool flag = true; int sign = 1; for(int i = 0; i < n; i++) { if(isalpha(str[i])) { return sum; } else if(str[i]==' '&&flag) { continue; } else if(str[i]>='0' && str[i]<='9') { sum = 10*sum + sign*(str[i] - '0'); flag = false; } else if(str[i] == '-' &&flag) { sign = -1; flag = false; } else if(str[i] == '+' && flag) { flag = false; } else { return sum; } if(sum > INT_MAX) { return INT_MAX; } else if(sum < INT_MIN) { return INT_MIN; } return sum; } };
- C++标准库中提供了判断是否是数字的接口
isdigit和判断是否是字母的接口isalpha。
- 使用以下代码能加速代码的运行速度,这段代码会停止C++和C输入输出流的同步,并且解除
cin和cout的捆绑,这里 有更详细的解释。效果很明显,将其添加到我的代码中,将我的代码的运行时间从20ms提升至8ms。
static int fast = []() { ios_base::sync_with_stdio(0); cin.tie(0); cout.tie(0); return 0; }();
Reference
- 字符到数字的转换,这个涉及到ascii码表的记忆,如果记不住了可以直接使用'0' 'a' 'A'
-
MapReduce模型
序言
对于mapreduce的兴趣起源于我最近在学习javascript时遇到了map和reduce函数。使用这两个函数进行数据处理时,总感觉思路有一点奇特,理解起来需要绕一个弯子。之前在学python时,也看到过这两个函数,但是当时没有在意,现在我觉得我有必要对这两个函数做一个深入的研究了。
什么是MapReduce
MapReduce的深层概念远比两个函数来得复杂,它是一个编程模型,主要用于解决大数据处理问题。使用这种模式编写的程序是可并行的(parallelized)并适用于大型计算机集群。运行时由系统自动对输入数据进行分割、协调多机器间的计算任务、进行异常处理、管理机器间的内部通信。这样,没有并行计算和分布式系统相关经验的开发人员也能够借助大型分布式系统进行数据处理了。
百度百科中给出的定义比较全面,而且很准确。
MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。map和reduce
从编程语言的角度上来说
map操作会接收到两个参数,一个列表和一个变换过程,其功能是将这个变换过程映射到每一个列表成员上,从而得到一个新的列表。
reduce操作也会接收到两个参数,一个列表和一个变换过程,其功能是将这个变换过程从前向后作用在列表成员上,最终得到一个列表中条目。从分布式系统的角度上来说 (以下内容摘自百度百科)
简单说来,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如前面的例子里,有人发现所有学生的成绩都被高估了一分,它可以定义一个“减一”的映射函数,用来修正这个错误。)。事实上,每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。
而化简操作指的是对一个列表的元素进行适当的合并(继续看前面的例子,如果有人想知道班级的平均分该怎么做?它可以定义一个化简函数,通过让列表中的元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到了平均分。)。虽然他不如映射函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。我之前在学习语言层面的map和reduce时,很难理解其用途,结合分布式计算的背景知识,就能够较形象地理解map和reduce操作的过程和作用。
并行计算与大数据
mapreduce模型给并行计算带来了革命性的影响,它是目前为止最成功、最广为接受和最易于使用的大数据并行处理技术。
mapreduce最初由google提出,并开发出了如下产品
- Google File System(大规模分散文件系统)
- MapReduce (大规模分散FrameWork)
- BigTable(大规模分散数据库)
- Chubby(分散锁服务)
随后就有其对应的开源实现,也就是Hadoop。Hadoop是Apache软件基金会发起的一个项目,它是一种分布式数据和计算的框架,它包含许如下子项目。
- HDFS,hadoop distributed file system,是Google File System的开源实现
- MapReduce,是Google MapReduce的开源实现
- HBASE,类似Google BigTable的分布式NoSQL数据库
- Zookeeper,分布式锁服务,类似Google Chubby
- Google File System(大规模分散文件系统)
-
每周算法:字符串锯齿变换
Description
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N A P L S I I G Y I R
And then read line by line: "PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:
string convert(string s, int numRows);Example 1:
Input: s = "PAYPALISHIRING", numRows = 3
Output: "PAHNAPLSIIGYIR"Example 2:
Input: s = "PAYPALISHIRING", numRows = 4
Output: "PINALSIGYAHRPI"
Explanation:P I N A L S I G Y A H R P I
Solution
Approach 1 找规律
我想到的第一个方法就是找规律,通过寻找每一行的变化规律,编写相应的计算逻辑。
需要注意:- 有符号数和无符号数的比较,这个是非常容易出错的,不要在有符号和无符号数之间进行比较。
- 特殊情况,也就是只有一行的情况,这个情况不需要进行转换,直接返回原字符串就好。
string convert(string s, int numRows) { int len = s.length(); assert(numRows > 0); int base = 2*numRows - 2; if (base == 0) { return s; } string ans; // 第一行和最后一行需要进行特殊处理 // 第一行 int i = 0; while (base*i < len) { ans += s[base*i]; ++i; } // 中间行 for (int j=1; j<numRows-1; ++j) { i = 0; while (base*i - j < len) { if (base*i - j >=0 ) { ans += s[base*i-j]; } if (base*i + j < len) { ans += s[base*i+j]; } ++i; } } // 最后一行 int lastStart = numRows - 1; i = 0; while (lastStart + base*i < len) { ans += s[lastStart + base*i]; ++i; } return ans; }
Approach 2 Sort by Row
这个方法是leetcode提供的一个方法,主要思路是使用一个二维矩阵将字符串按照顺序存储起来,时间复杂度为
O(n),空间复杂度为O(n)。string convert(string s, int numRows) { if (numRows == 1) return s; vector<string> rows(min(numRows, int(s.size()))); int curRow = 0; bool goingDown = false; for (char c : s) { rows[curRow] += c; if (curRow == 0 || curRow == numRows - 1) { goingDown = !goingDown; } curRow += goingDown ? 1 : -1; } string ret; for (string row : rows) ret += row; return ret; }
Approach 3 Visit by Row
这个方法是leetcode提供的另一个方法,通过计算下标完成字符串的转换,实际上也是对转换的规律进行了总结,时间复杂度为
O(n),空间复杂度为O(1)。
对于空间复杂度,实际上需要额外的空间存储结果字符串,如果忽略函数所返回的结果字符串,则空间复杂度为O(1)。string convert(string s, int numRows) { if (numRows == 1) return s; string ret; int n = s.size(); int cycleLen = 2 * numRows - 2; for (int i = 0; i < numRows; i++) { for (int j = 0; j + i < n; j += cycleLen) { ret += s[j + i]; if (i != 0 && i != numRows - 1 && j + cycleLen - i < n) ret += s[j + cycleLen - i]; } } return ret; }
- 有符号数和无符号数的比较,这个是非常容易出错的,不要在有符号和无符号数之间进行比较。
-
css flexbox 总结
引言
本文主要对css flexbox的关键点了总结,方便以后在以后的查阅。
容器的属性
对于容器需要指定其显示方式为flexbox
display: flex;
指定flex排列的方向、在排列时是否会换行,使用
flex-flow可以快速设置二者属性flex-direction: row | row-reverse | column | column-reverse; flex-wrap: nowrap | wrap | wrap-reverse; flex-flow: <'flex-direction'> || <'flex-wrap'>;
用于调整主轴方向的排布(对于
row来说就是横向,对于column来说就是纵向)justify-content: flex-start | flex-end | center | space-between | space-around | space-evenly;
用于调整相交轴方向的行间排布(对于
row来说就是纵向,对于column来说就是横向)align-content: flex-start | flex-end | center | stretch | space-between | space-around;
用于调整相交交轴方向的单行对齐方式。需要注意的是其中
center和baseline的区别: 二者都表示居中,而baseline会保证所有文字的底边处在同一条线上。align-items: flex-start | flex-end | center | baseline | stretch;
条目的属性
用于调整顺序
order: <integer>; /* default 0 */
用于调整每个条目的伸展程度
flex-grow: <number>; /* default 0 */
用于调整每个条目的缩小程度
flex-shrink: <number>; /* default 1 */
用于调整每个条目的默认尺寸
flex-basis: <length> | auto; /* default auto */
设置flex属性,排列顺序为
flex-grow,flex-shrink,flex-basisflex: none | [ <'flex-grow'> <'flex-shrink'>? || <'flex-basis'> ];
用于重载容器的
align-items的设置align-self: auto | flex-start | flex-end | center | baseline | stretch;
-
emacs的键盘宏(keyboard macro)
对于一些有规律且重复性的编辑任务, 手动完成十分无聊, 并且需要耗费较长的时间。我在youtube上看到一个使用keyboard marco的 视频 后, 受到很大的启发, 在以后的使用中也会尝试使用宏。我总结了一下视频中的技巧要点,并查阅资料对相关知识点进行了补充和完善。
有梯子的同学可以去看看,视频地址:https://youtu.be/wFCO__0prCM
操作指令
开始记录宏: 命令名称kmacro-start-macro, 快捷键C-x-(或<f3>
结束记录宏: 命令名称kmacro-end-macro, 快捷键C-x-)或<f4>
执行宏: 命令名称kmacro-end-and-call-macro, 快捷键C-x-e, 可以使用C-u指定这个宏的执行次数
清除多余的空格: 命令名称fixup-whitespace, 这个命令我是第一次见到, 以后可以尝试多用用。参考资料
-
每周算法:最长对称子串
Description
Given a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.
Example 1:
Input: "babad"
Output: "bab"
Note: "aba" is also a valid answer.Example 2:
Input: "cbbd"
Output: "bb"Solution
我想到了两种方法:暴力解法、从中心展开
Approach 1 暴力解法
暴击解法的时间复杂度为
O(n3), 找出所有子串的时间复杂度为O(n2), 判断一个子串的时间复杂度为O(n); 空间复杂度为O(1)。需要注意的是,如果子串过短,就没有必要进行对称性判断了。
下面是我的代码
bool isPalindrome(const string& str) { int len = str.length(); if (len <=0) { return false; } int head = 0; int tail = len - 1; while (head < tail) { if (str[head] != str[tail]) { return false; } ++head; --tail; } return true; } string longestPalindrome(string s) { string ans = ""; for (size_t i=0; i < s.length(); ++i) { for (size_t j=s.length()-i; j != 0; --j) { if (ans.length() >= j) { continue; } string temp = s.substr(i, j); if (ans.length() < temp.length() && isPalindrome(temp)) { ans = temp; } } } return ans; }
Approach 2 从中心展开
从中心展开方法的时间复杂度为
O(n2), 空间复杂度为O(1)。需要注意的是坐标的计算,这个在字符串处理题目中是十分关键的,也是很容易出错的。
由于单个字符和两个相同字符都可以作为中心,这点需要额外注意一下。下面就是我的解法,使用的C++做的。
string longestPalindrome(string s) { string ans = ""; for (size_t i=0; i < s.length(); ++i) { // 如何确定初始的边界很重要 size_t j = i; size_t k = i; // 向两边拓展边界 while (j-1>=0 && s[j-1]==s[i]) { --j; } while (k+1<s.length() && s[k+1]==s[i]) { ++k; } while (j-1>=0 && k+1<s.length() && s[j-1]==s[k+1]) { --j; ++k; } if (k-j+1 > ans.length()) { ans = s.substr(j, k-j+1); } } return ans; }
leetcode上还有一个解法,使用java完成的,它的坐标计算也很有技巧性。
public String longestPalindrome(String s) { if (s == null || s.length() < 1) return ""; int start = 0, end = 0; for (int i = 0; i < s.length(); i++) { int len1 = expandAroundCenter(s, i, i); int len2 = expandAroundCenter(s, i, i + 1); int len = Math.max(len1, len2); if (len > end - start) { start = i - (len - 1) / 2; end = i + len / 2; } } return s.substring(start, end + 1); } private int expandAroundCenter(String s, int left, int right) { int L = left, R = right; while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) { L--; R++; } return R - L - 1; }
Approach 3 动态规划(dynamic programming)
leetcode上还给给出了使用DP解决这个问题的方法。
我在leetcode上的discuss上找了个java写的解法。动态规划的时间复杂度为
O(n2), 空间复杂度为O(n2)。
我对dp算法的了解还不多,个人感觉值得思考的是i和j的变化起点和变化方向。public String longestPalindrome(String s) { int n = s.length(); String res = null; boolean[][] dp = new boolean[n][n]; for (int i = n - 1; i >= 0; i--) { for (int j = i; j < n; j++) { dp[i][j] = s.charAt(i) == s.charAt(j) && (j - i < 3 || dp[i + 1][j - 1]); if (dp[i][j] && (res == null || j - i + 1 > res.length())) { res = s.substring(i, j + 1); } } } return res; }
Approach 4 Manacher算法
这个算法思路实在是新奇,感兴趣的同学可以 去看看 。
-
每周算法:最长不含重复字符的子串
Description
Given a string, find the length of the longest substring without repeating characters.
Examples:
Given "abcabcbb", the answer is "abc", which the length is 3.
Given "bbbbb", the answer is "b", with the length of 1.
Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer must be a substring, "pwke" is a subsequence and not a substring.来源:LeetCode 03 Longest Substring Without Repeating Characters
Solution
好久没刷算法题了,手有点生,没有什么思路,下面的答案是看过提示之后才写出来的。
Approach 1 暴力解法
将所有的子串都穷举出来,并对它们进行判断,就能够得到最长子串的长度。这个算法很显然需要耗费很长时间。
需要注意的是: C++20中才支持std::set::contains这个接口(根据cppreference.com)。bool isStringWithUniqueString(const string& str) { // 用于判断字符串是否是具有唯一字符的 set<char> setChar; for (size_t i = 0; i<str.length(); ++i) { if (setChar.find(str[i]) != setChar.end()) { return false; } setChar.insert(str[i]); } return true; } int lengthOfLongestSubstring(string s) { int lengthMax = 0; for (size_t i=0; i<s.length(); ++i) { for (size_t j=i+1; j<=s.length(); ++j) { // get sub-string string strTemp = s.substr(i, j-i); if (isStringWithUniqueString(strTemp)) { lengthMax = max(lengthMax, (int)strTemp.length()); } } } return lengthMax; }
Approach 2 滑动窗口
滑动窗口的概念在字符串处理问题中十分常用,保持子串的左端点不动,不断拓展右侧端点,就能穷举出所有满足条件的子串。
需要注意的是这句话:lengthMax = max(lengthMax, int(j-i+1));-
std::max并不能同时匹配int和size_t,所以需要进行强制类型转换。
- 在完成第
j个字母的验证后,说明包含该字母的子串也满足条件,所以要进行+1操作,这个主要是针对只有一个字母的字符串。
int lengthOfLongestSubstring(string s) { int lengthMax = 0; for (size_t i=0; i<s.length(); ++i) { // 这个循环目的是,验证从i到j的字符串是否满足条件 set<char> setChar; for (size_t j=i; j<s.length(); ++j) { char ch = s[j]; if (setChar.find(ch) != setChar.end()) { break; } else { lengthMax = max(lengthMax, int(j - i + 1)); } setChar.insert(ch); } } return lengthMax; }
Approach 3 优化的滑动窗口
使用
map对字母出现的位置进行记录,这样在出现相同字母时,就能够从上一次出现的位置向后开始寻找。
需要注意句话it->second+1>=i, 需要对位置加1后再比较,这样才能保证i的坐标计算正确。int lengthOfLongestSubstring(string s) { int lengthMax = 0; map<char, size_t> mapPos; for (size_t i=0, j=0; j<s.length(); ++j) { char ch = s[j]; map<char, size_t>::iterator it = mapPos.find(ch); if (it != mapPos.end()) { // 这里说明找到了字符上一次出现的位置 if (it->second + 1>= i) { i = it->second + 1; } } lengthMax = max(lengthMax, int(j - i + 1)); mapPos[ch] = j; } return lengthMax; }
-
-
提高emacs中浏览和选择操作效率的技巧
1 引言
Gaurab Paul的 一篇博文 给了我很大的启发,他详细地介绍了emacs中的相关概念,并提供了许多充满想象力的小技巧。作为emacs的入门级选手确实学到了很多,也拓宽了自己的思路。
我最初的开发环境是Visual Studio,这一类比较大型的IDE集成了许多功能,但同时也会束缚住使用者的想法。通过这篇文章我感受到的由普通操作指令能组合成的新编辑方式。
如果英文水平允许的话,非常推荐阅读一下原版的博文,原文中有更加丰富形象的图片示例,无论是跟我一样刚刚入门emacs的新手,还是经验丰富的老兵,都能够从中获得启发。下面,我结合自己的理解和收获谈谈emacs中操作的体会。
2
point、mark和region的概念我之前进行代码段复制的操作是十分基础的,用
C-@模拟鼠标按下,方向键模拟鼠标拖动,在鼠标拖动的过程中就形成了一个选区,然后用M-w对这个选区进行复制操作,用C-y粘贴被复制的内容。以上操作带出了几个非常重要的概念 。在emacs中,鼠标光标所在位置被称作
point;组合键C-@执行的是set-mark-command命令,就是将point所在位置标记为mark;通过移动光标,也就是移动point后,在point与mark之间就形成了region。3
region操作技巧3.1 调整
region的大小下面就来介绍一个非常重要的命令
exchange-point-and-mark,这个命令默认被绑定在组合键C-x C-x上,从字面意思上很容易理解这条指令的作用,就是交换mark和point的位置。这样做的意义在于能够方便地切换region的可动边界,这样能够使region方便地分别从两端调整大小。
下面的示例是截取自Paul的博文,需要注意的是,他习惯于使用C-SPC调用set-mark-command。Lorem ipsum dolor sit amet ^ Cursor Point | Mark | Lorem ipsum dolor sit amet ^ C-spc Mark Point | ----region--| | | Lorem ipsum dolor sit amet move ^ forward -> Mark Point | ----region--| | | Lorem ipsum dolor sit amet ^ C-x C-x Point Mark | ----region--| | | Lorem ipsum dolor sit amet Point and mark interchanged3.2 使用
region进行重复性输入对于
region相关的操作,通常是对已经存在的代码段进行编辑的,如果我们在输入之前就知道有许多字段是需要重复输入的,那么就可以在输入之前设置好mark,对输入后形成的region完成复制。这个技巧在特定情况能够很大地提升输入效率,但是我个人认为,想要在实战中完成这个操作,还需要保证非常清晰的思路。可以通过下面的示例感受这种操作带来的方便(示例截取自Paul的博文)。
下面给出了详细的操作解析
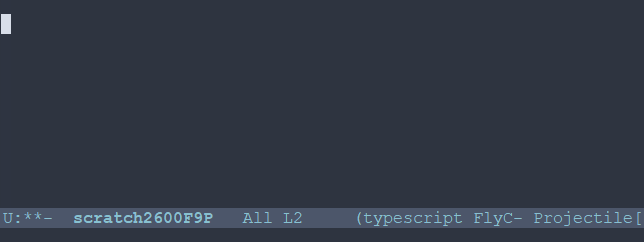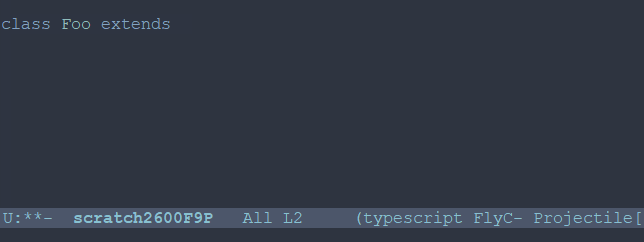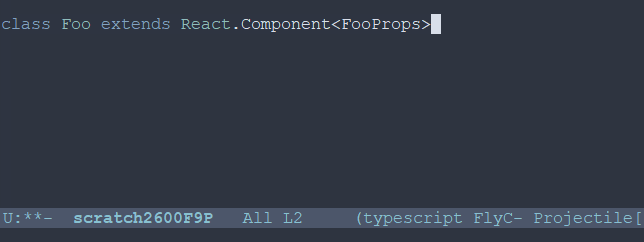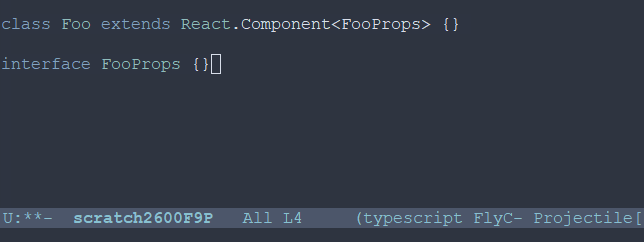
class ^ C-spc => Activate mark class Foo ^ M-w => Foo has now been killed (copied) class Foo extends React.Component< ^ C-spc => Activate mark class Foo extends React.Component< ^ C-y => Yank (paste) Foo class Foo extends React.Component<FooProps ^ M-w => FooProps has now been killed (copied) class Foo extends React.Component<FooProps> // Later interface ^ C-y => Yank FooProps interface FooProps {}3.3 框选一个矩形的
region使用
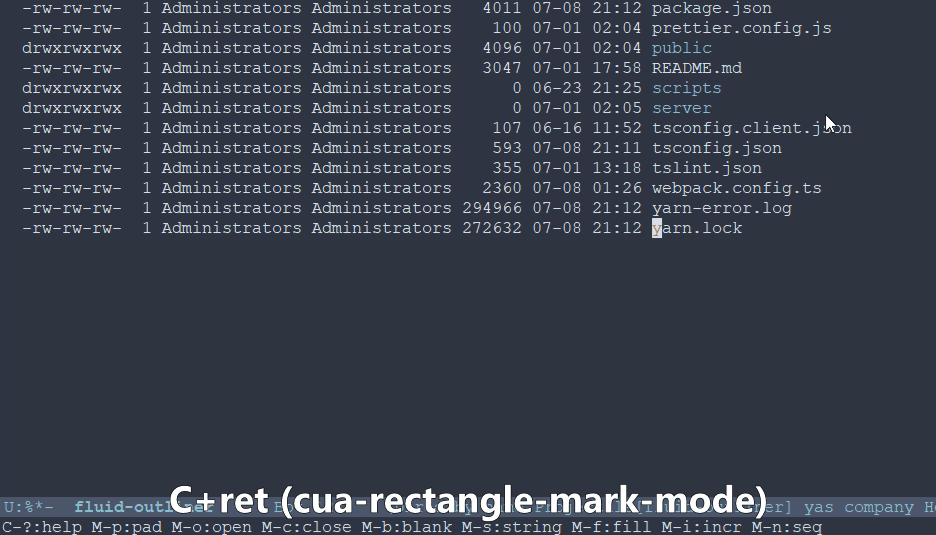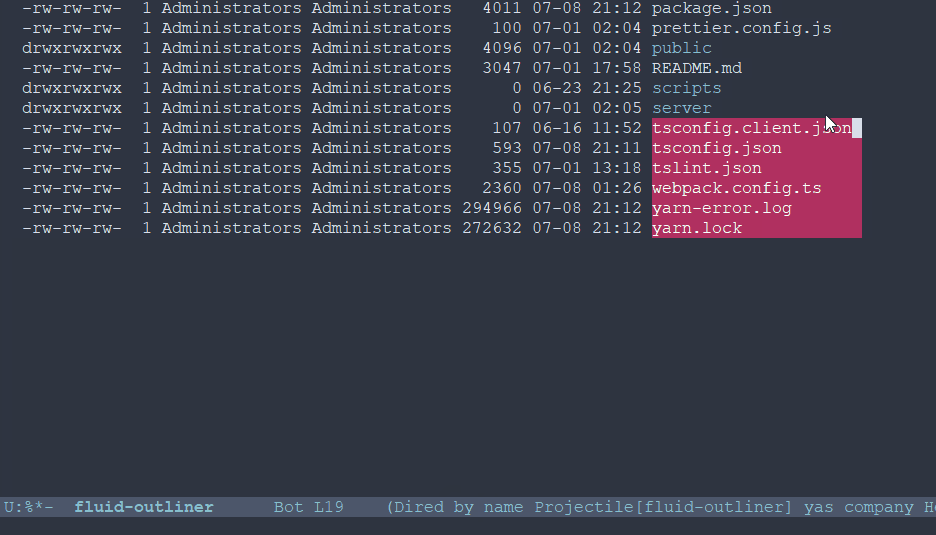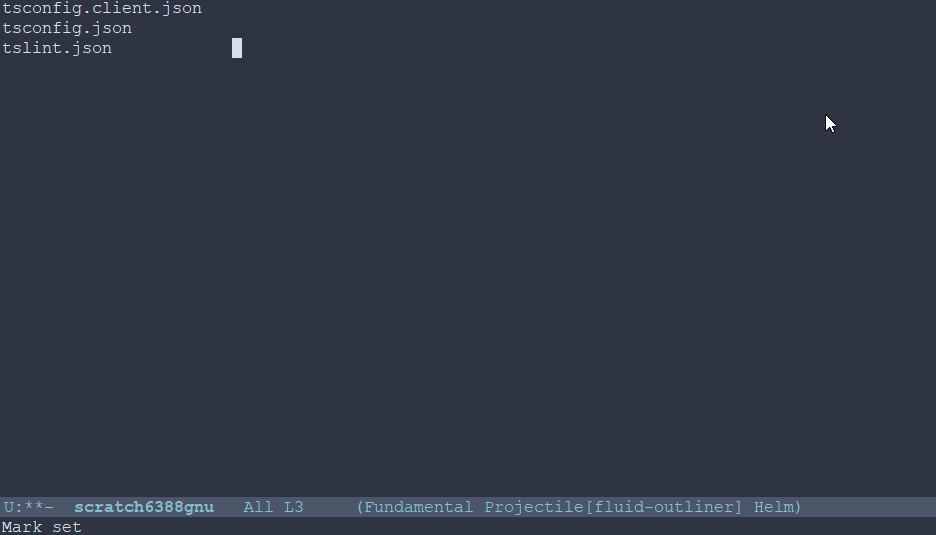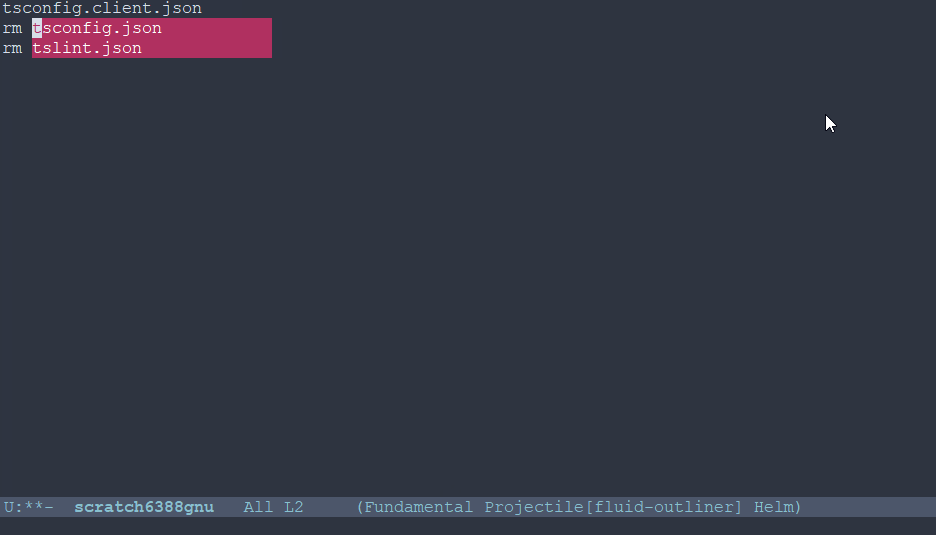
rectangle-mark-mode命令,默认快捷键C-x-SPC,能够框选出一个矩形的region。对于矩形region,Paul给出的示例是复制dired中的多个文件名称,貌似其他合适的使用场景不太多。4 其他插件支持
有些插件拓展能够实现光标的快速定位,如 helm-swoop 和 avy 。
4.1 helm swoop
4.2 avy
avy 的思路非常独特,这样的跳转和定位让我想起了Chrome浏览器中的Vimium插件,他允许我们使用更少的按键就能跳转到当前buffer中的任意位置,略微遗憾的是它只支持拉丁字母,不过在编写代码的大多数情况下是够用的。
下面的图片来自Paul的博文
5 参考资料
-
shell的输出重定向
引言
在linux中借助shell等命令行工具能够很方便地与操作系统交互,可以在shell中将命令或程序的输入结果重定向到特定地方,很方便地实现一些功能。这个技巧十分实用,使用输出重定向能够极大地简化我们的日常操作。
使用尖括号完成重定向
示例如下,运行下面的命令能够把
ls命令的运行结果写入到ls-output.txt中。使用>会把程序运行时本该输出到stdout的内容重定向到指定名称的文件中。ls . > ls-output.txt
可以在
>左面写上数字和&,用以标识在重定向时的特殊用法。下面会给出一些特殊用法的实例。重定向
stdout到指定文件中ls . 1> ls-output.txt
重定向
stderr到指定文件中ls . 2> ls-error.txt
将
stdout和stdout合并再重定向到指定文件中ls . 2>&1 ls-output-and-error.txt
以下命令具有相同的效果
ls . &> ls-output-and-error.txt
将程序的输出丢掉
可以将输出重定向到一个特殊的文件
/dev/null,所有写入到这个文件的内容都会被丢弃掉。program > /dev/null
将输出追加到指定文件尾部
使用一个尖括号(
>)能够将输出重定向到文件中,在写入文件时会覆盖掉其中的内容。如果想保留文件中的原始内容,则可以用两个尖括号(>>),这样就能将输出追加到文件的尾部。示例代码如下:echo test >> file-output.txt
使用管道完成重定向
使用管道符号
|能够将一个程序的输出重定向到另一个程序的输入中去。下面的命令会将ls的输出(stdout)重定向到grep的输入(stdin)中去。管道命令在linux中是最常见的用法。ls | grep <pattern>
-
libshmcache源码阅读笔记
引言
由于在工作中需要开发一套内存缓存服务,使用了共享内存作为多进程间的数据共享。为了提高共享内存缓存服务的性能,我找了一个类似的较为成熟的开源项目 libshmcache ,通过研究源码学习其中的优点并改进自己的模块。
libshmcache与redis相似的是都使用内存进行数据缓存;与redis不同的是,redis使用的进程自己申请的动态内存,而libshmcache使用的是共享内存。使用共享内存就意味着libshmcache主要的应用场景是同一台主机上的数据缓存。
我花了一周时间阅读了比较感兴趣的部分代码,收获不少,现就以下几个方面总结一下自己的心得:
- 纯C语言开发的代码风格
- hash table的原理和实现
- gcc原子化操作接口
- 有锁写和无锁读的实现细节
- 共享内存的两套函数接口(POSIX和SystemV)
纯C语言开发时的代码风格
我在工作中使用比较多的开发语言是C++,对于C语言编写的这样规模的项目,还是第一次仔细深入地研究。C语言使用
struct作为大多数自定义数据结构的关键字,相对于C++能够使用成员函数能够对类进行功能拓展,C语言比较常用的是将这个对象作为输入参数传到函数中。纵观所有项目代码,我感受比较深的就是使用结构体中嵌套匿名结构体,这样做能够增强数据结构的层次感,示例代码如下:
struct shmcache_context { pid_t pid; int lock_fd; //for file lock int detect_deadlock_clocks; struct shmcache_config config; struct shm_memory_info *memory; struct { struct shmcache_segment_info hashtable; struct { int count; struct shmcache_segment_info *items; } values; } segments; struct shmcache_value_allocator_context value_allocator; struct shmcache_list list; //for value recycle bool create_segment; //if check segment size };
注意
shmcache_context中的匿名结构体segments和values,这样的写法体现了相互包含关系,也使后续的操作该数据结构的语句更加容易理解。另外对于联合体和位域这两种技术也是我在之前开发中使用比较少的,通过阅读源码能够让我对其有了更深刻的理解。示例代码如下:
union shm_hentry_offset { int64_t offset; struct { int index :16; int64_t offset :48; } segment; };
这段代码使用了联合体赋予了
shm_hentry_offset两种访问方式,又使用了位域将int64_t分割为两段。hash table的原理和实现
libshmcache内部使用的是hash table做内部缓存的数据结构,这使查找的时间复杂度是O(1)。
之前看过一些介绍hash table的资料,对hash table的工作原理是有过一个基础的了解的,这次通过阅读源码,能够了解到hash table在代码实现上更加细节的内容。
对于hash计算中出现的hash值冲突,即在hash计算时出现了两个不同的key在经过hash计算后得到的bucket相同,libshmcache采用的解决方案是使用linked list来存放这些相同bucket对应的value。gcc原子化操作接口
使用原子化操作接口能够解决一些并发读写问题,原子化操作相对于互斥锁执行更快。原子化操作也是一种无锁编程的方式。
有锁写和无锁读的实现
在libshmcache中,写操作通过
pthread_mutex_t进行同步,而读操作是无锁的。
对于写操作来说,需要对hash table进行操作,这肯定是需要同步的。
将pthread_mutex_t保存在共享内存中,不同的进程通过映射共享内存就能获得同一个互斥量,通过这个互斥量就能完成进程间同步。共享内存的两套函数接口(POSIX和SystemV)
在linux上使用共享内存时有两套接口
mmap和shmget。mmap是POSIX标准的接口,而shmget是System V标准的接口,两者都能够实现进程间共享内存,但他们在使用上还是有些区别的。对于mmap来说,需要在硬盘上创建一个文件,再将该文件映射到内存中。对于shmget来说,需要指定一个key,不同的进程通过相同的key就能映射到同一片内存。 - 纯C语言开发的代码风格